
Lightweight translation application that supports light/dark themes, with Melo# you can:
. Write any text or sentence in your own language and Melo# will repeat it in the language of your choice
. Spell a sentence in your own language so Melo# will transcribe it and repeat it in the desired language
. Translate any sentence using a natural voice
. Switch rapidly between two languages for a bi-directionnal conversation
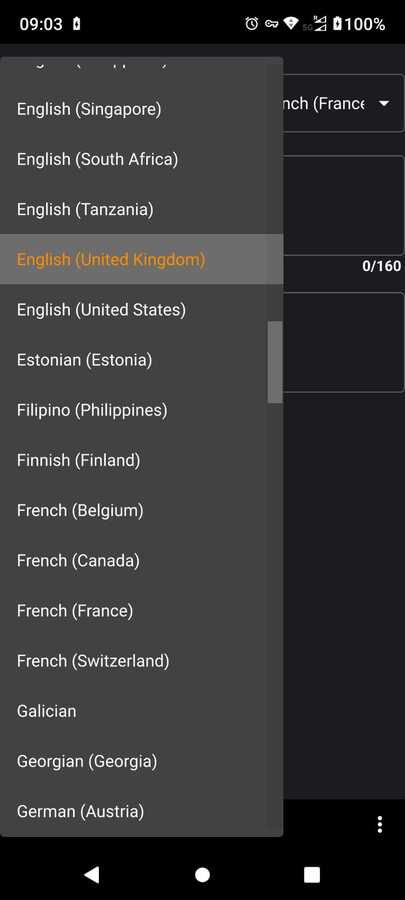
. Choose from 100+ languages
. High quality voice recognition using cloud AI and machine learning enhanced audio
This is quite useful to communicate when your interlocutor speaks a foreign language or if you are unable to speak.
Why do you need another translator?
The idea was not about reinventing the wheel, I was looking for something simple in can use while travelling. A big button, I speek, it repeats out loud in the language of my choice. I could not find that, so decided to create my own.
What technologies are needed here:
First a good framework, so I used Qt6 to make things easy, I can write a code on my laptop, test it, then recompile it for Android and IOS so anyone can use it on his phone, this is a multiplatform development tool. Qt allows to mix languages depending on your needs. I use QML for the UI, Javascript for light operations and prototyping, then c++ for heavy duty calculations. I also had to use platform native language for on device speech recognition (Java on Android, Objective-c on ios). There no language that fits it all, but I enjoy using the language that fits a specific requirement, and blend it with others, in the same project.
To compile the 3rd party Opus library and link it with my project, as it is not part of Qt by default, I built it for each specific platform using cmake (this tool is very handy). I only had to do this once per target. Finding the toolchain for ios required some research but I found a good one on github.
Then I needed to master those 3 domains:
1) Speech to text
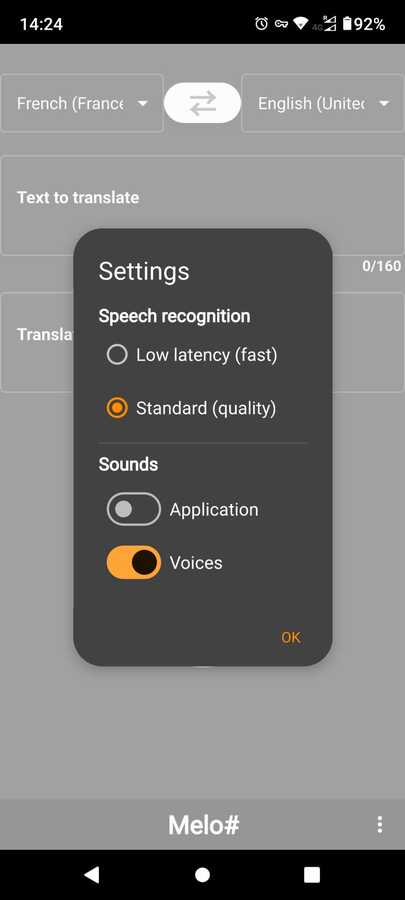
This was the most difficult part, finding the best technology, so I am giving the use the choice (in the option menu). With the low latency engine, this will use the recognition engine from your device if available (either Android speech recognizer or Apple SFSpeech Recognizer). The adavantage is that you can see the text being recognized and displayed as you speak. Also the processing is real time. However it lacks punctuation and some devices forbid profanity (either this is a good or bad thing, I am not the one to decide). So the experience is not a like to like for evenryone, but roughtly similar. It is the default setting. Quality of recognition is average.
There is also a quality mode (I really like this one). For this I used the latest opus codec which is doing a fantastic job here. I was originally going for a 48kbps compression to encode user's voice but the latest enhancements to the codec allowed me to go all the way down to 16kbps bitrate with very good results in recognition. I record my audio in pcm, encode the packets in a qthread and send them to Azure Speech AI to get my sentences back. Recording is limited to 60 seconds but this is plenty of time for each sentence of a conversation in real life. Opus compression works great even on older devices, the cpu usage is very low. I could avoid compressing and send the pcm packets straight to Azure, but pcm is too heavy, and I want my solution to work on seamlessly poor networks. Opus is just ideal.
For comparison, 1 minute of recording would be 5.76MB in pcm, and only 120kB with Opus, so PCM would take ages on most mobile network, unless you are in a town with a good 5G coverage, and even so, your device may take some time to send the packets. 10 seconds of recording, which is the usual use case, takes 960kB of pcm and only 20kB of Opus. So the compressed audio can be sent instantly.
This is not real time (but not really long) for Azure to send back the recognized text, I find the quality often superior to the embeeded engine. And it has punctuation with properly formated sentences. This does matter, because later on, the text to speech voice will prononce appropriately wether the sentence ends with a . or a ?
2) Translation
For this one I had to compare Google Translate to Azure translator. Google has much lower latency (returns translation faster), but Azure is once again on top in terms of quality, so I will stick to it. This overhead does not make much difference in real life scenario. So we are good.
3) Text to speech
I wanted to use the embeeded voice, so I would have sometihng native. However the naming scheme of voices on Android is not human friendly, I first decided to pick up a male and a female voice myself for each language, but this was too much work and maintainance. So I went against it and decided to go for a cloud solution, which once again is Azure Speech AI. There are many advantages here, a unified experience on all device, easy to maintain (I just need to parse the list of available list), and the supported languages more or less match the Speech to text and translator.
I only left out a couple of languages which were not supported end to end, but the list is quite massive (around 140), which you can use in any pair you like (eg French to Polish, Spanish to English, Croatian to Chinese, whatever).
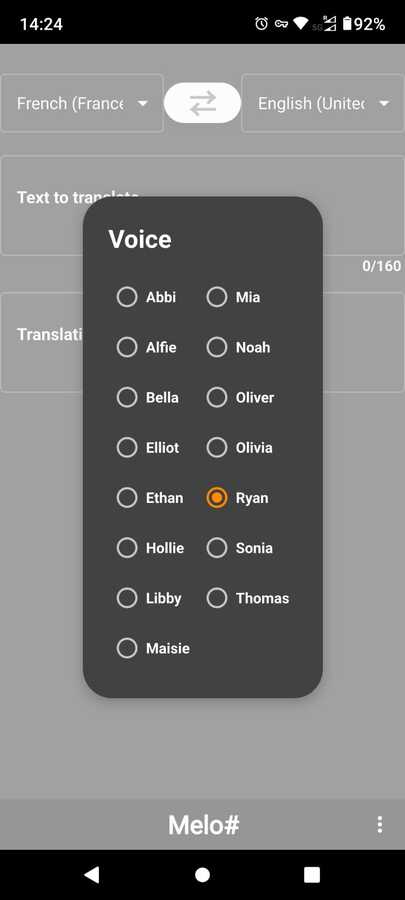
Azure Speech AI lets you choose from 460+ neural voices accross all these laguages, which is also a great addition.
The text is sent to Azure, which returns a recorded AI voice in the Opus for at 24kbps and 24khz, then I decode and upsample it to 48khz in a separate thread. The decoder is using the maximum complexity (10) to enable Opus machine learning (NoLace). The result is fairly good quality and network bandwith friendly. Decoding with the Opus codec is again cpu friendly. I am also using lbb i the codec which compensates in case of small packet loss during the network transmission.
Result: the whole thing is fast.
What about the UI?
I went straight for Material design 3, Qt made it easy to integrate with QML and this looks great to the eyes, I used it for every platform including ios. Finding good icons was not easy, Qt does not support woff2 so I add to find a font in ttf format. I didn't want to have each Icon separately as a png image as this would be a maintenance overhead. The default google font file is nearly 8MB, so this is to big as a ressource, I fod a nice alternative using Material Desing Icons from picoprogrammers, which is less than 2MB for the whole pack. Even if I use only a fraction of the icon set, the size cost is affordable. I put the fonts in an qrc file and load it from memory, so this is fast anyway.
The app will load in dark or light theme depending of you system preferences, but you can change the theme and add a backgound in the settings.
Freemium or premium?
I do not like ads so this is add free, I want everyone to use it so I opted for a freemium model on Google Play and the Apple Store. There is no hidden in-app purchase to use the application. All the functionalities are here by default.
Where is this available?
It available for free on all the major platforms (Android, macos, ios, Windows). I udpate regularly, when I have a new idea and if there is a platform update.
Dopping QMultimedia
It did the job for a while and is pretty well mainted, howver I needed something less bloated, too many codecs for me. Too save some room (and many GB for my users) I opted for miniaudio to capture audio from microphone and read my output, the opus codec doing the compression/decompression.
What About openssl on android?
I used the binaries provided by kdab for a while, but I like to use the latest, so now using an easy cmake implementation that allows me to do it.
Note about kdab
These devs know their stuff, they are providing high quality libraries I like to play with, for example the excellent kdbindings which avoid me from adding QObject macro everywhere for signals and slots.
| Download |
Go to the following page link Or get the software from your online store. |
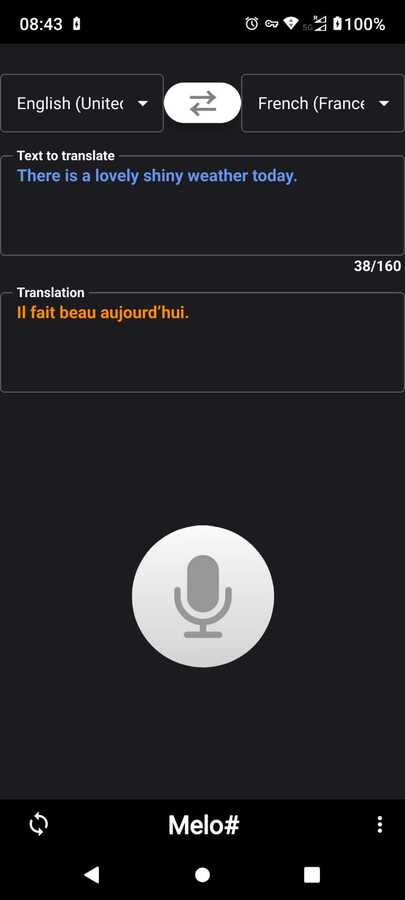
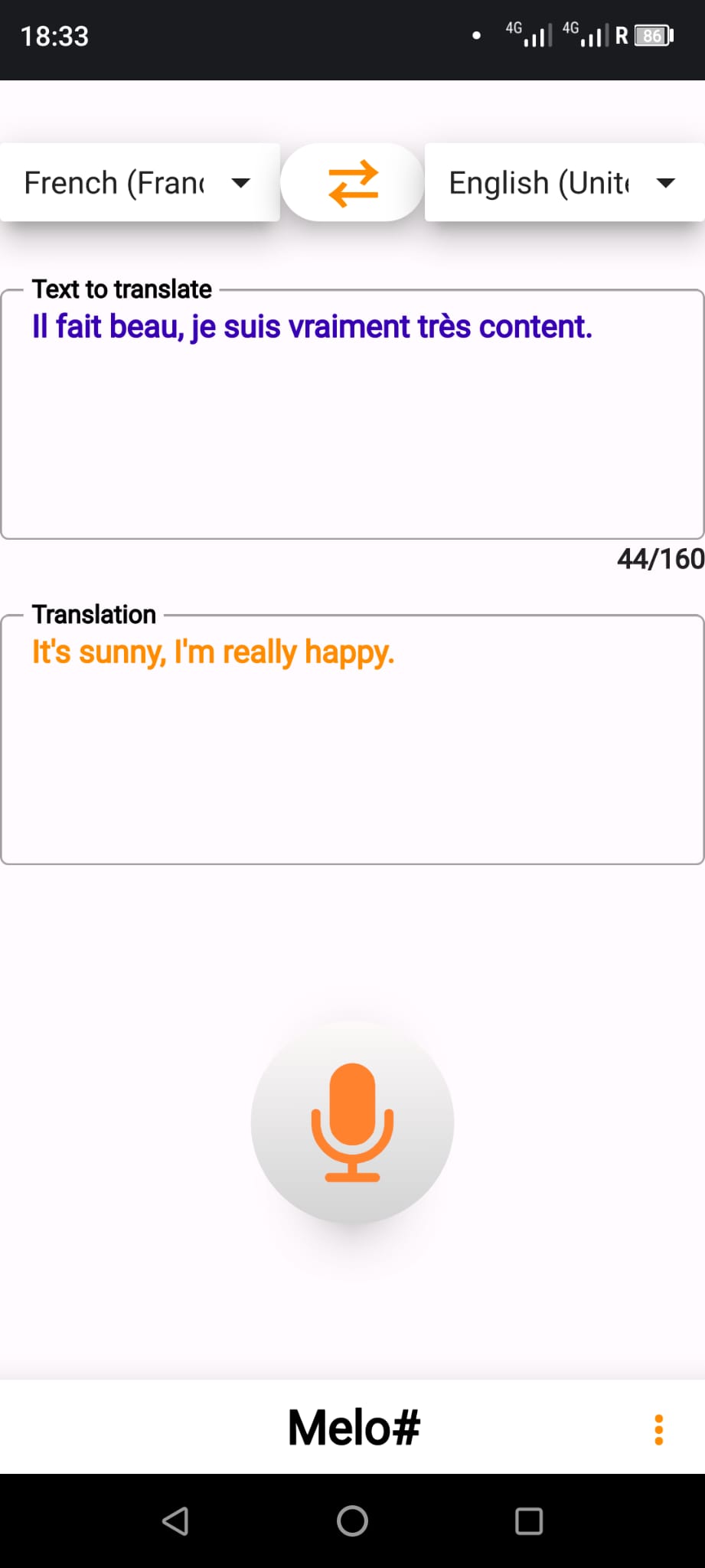 | Select between 100+ languages to translate. Type any sentence in the top box, then press enter so the translation will appear in the bottom box, and the speech synthesis will repeat it.
You can also press (o) to start a transcription, the transcribed sentence will appear in the top box.
|
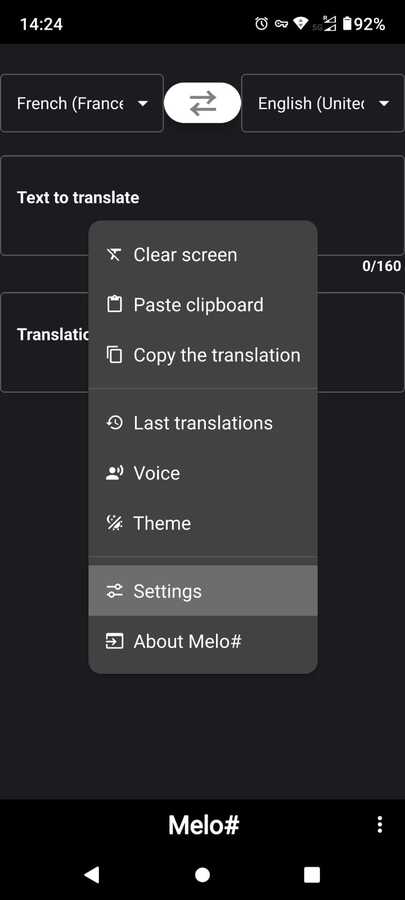
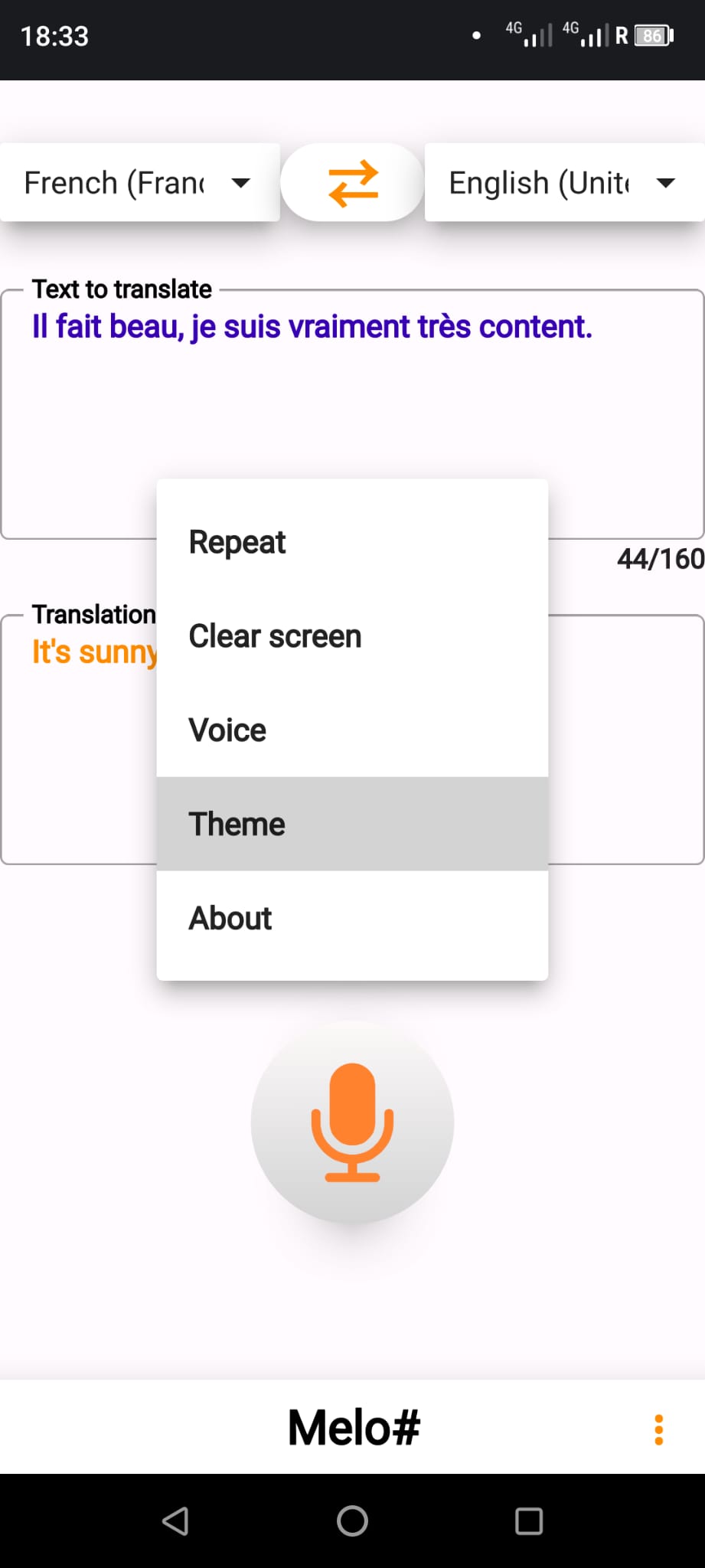 | Press the "menu" button at the bottom right corner of your screen to access the options.
You can then: a) Repeat the translated text. b) Clear the screen to write a new text to translate. c) Chage the output voice. d) Set your theme. |
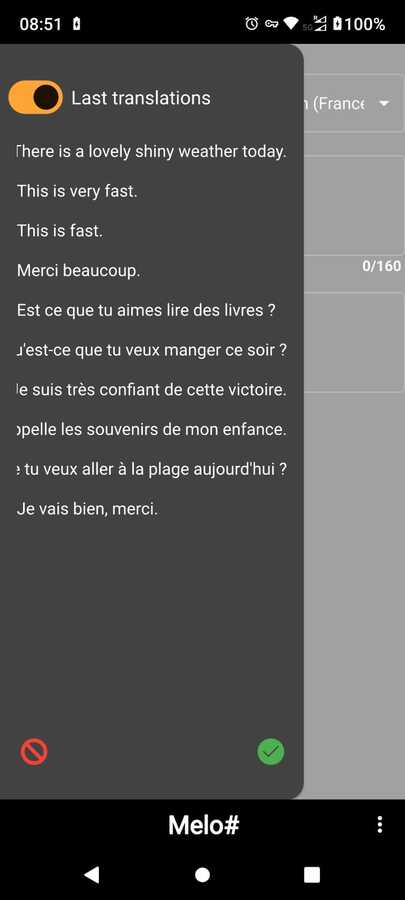
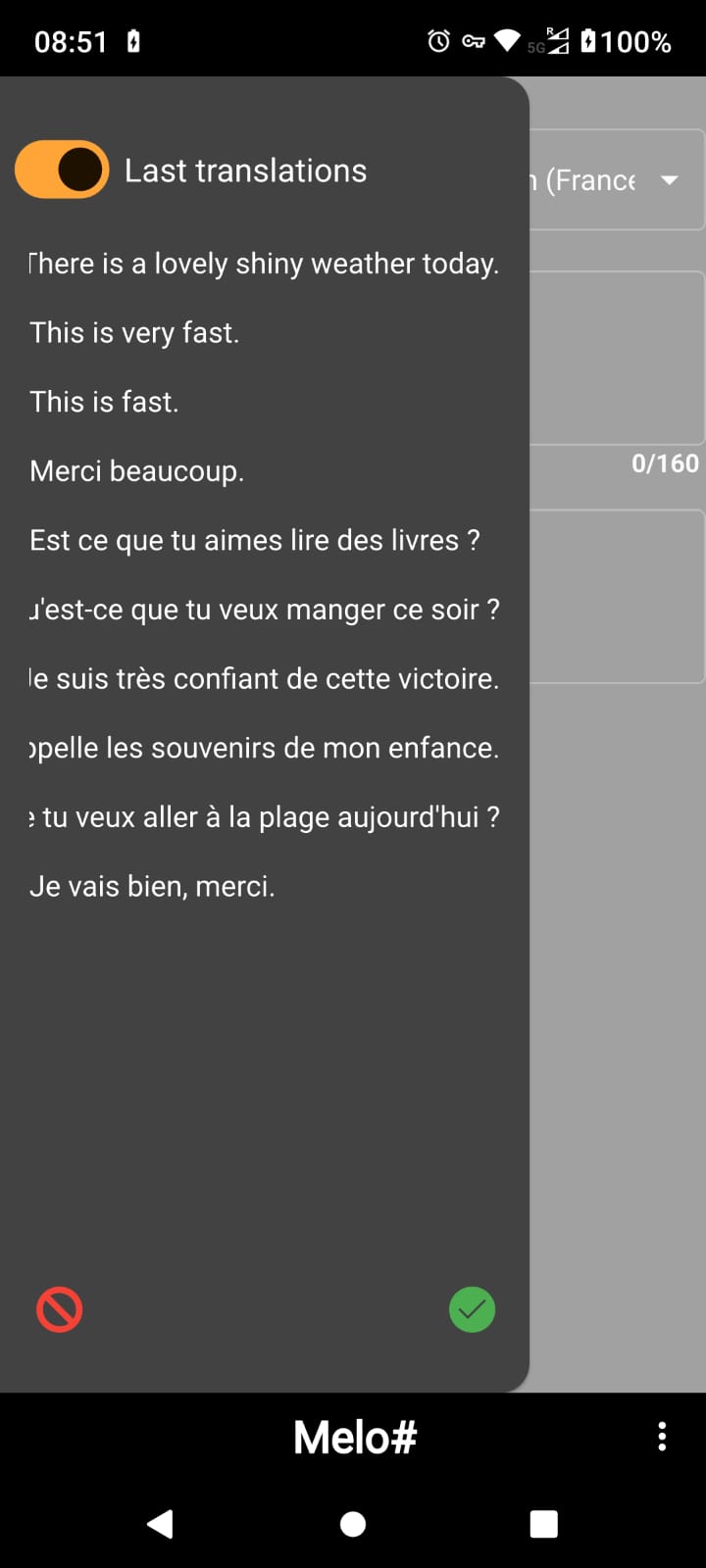 | You can keep track of the last 10 inputs. If you translate the same text twice. It will not be duplicated, but placed at the first position of the list. |
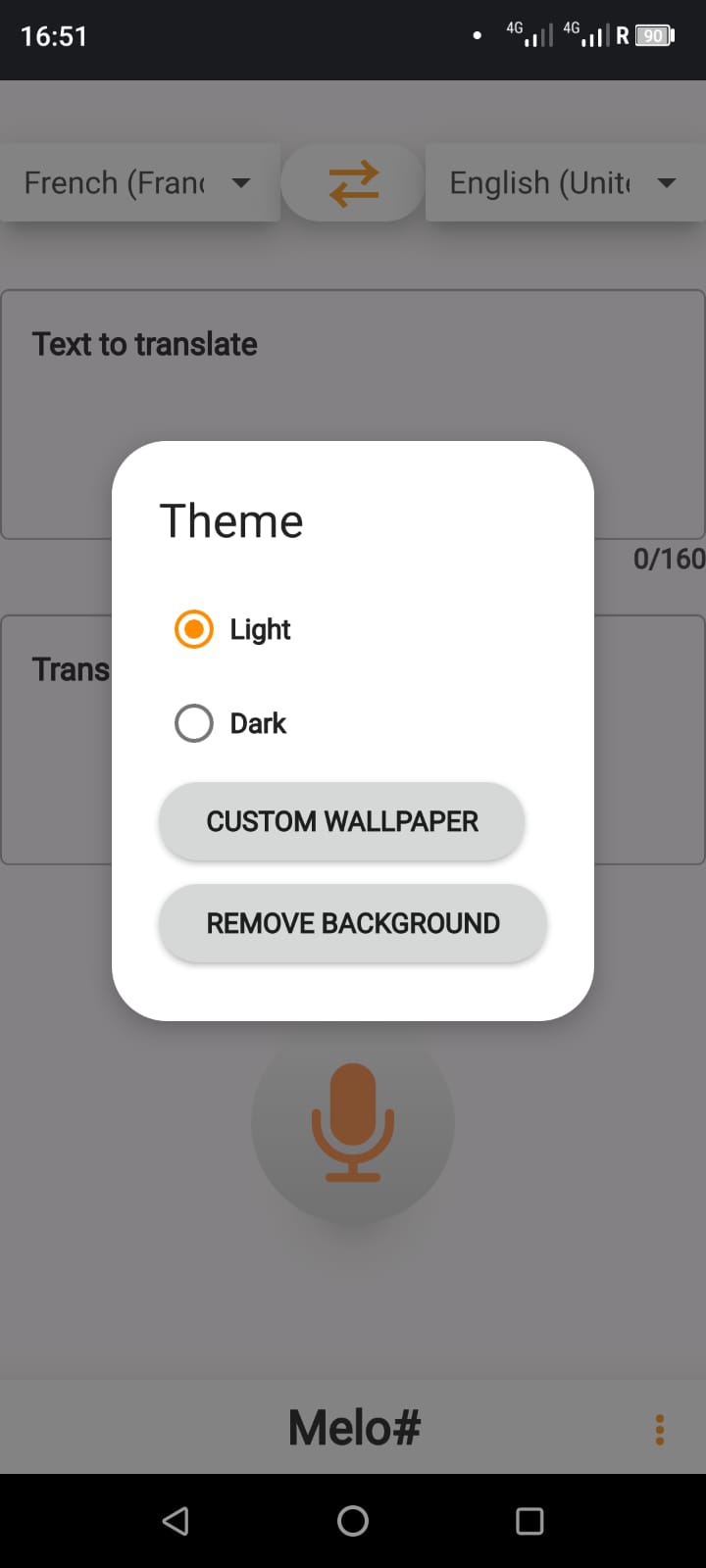 | The application is set to your system theme by default, but you can change it in the settings. |
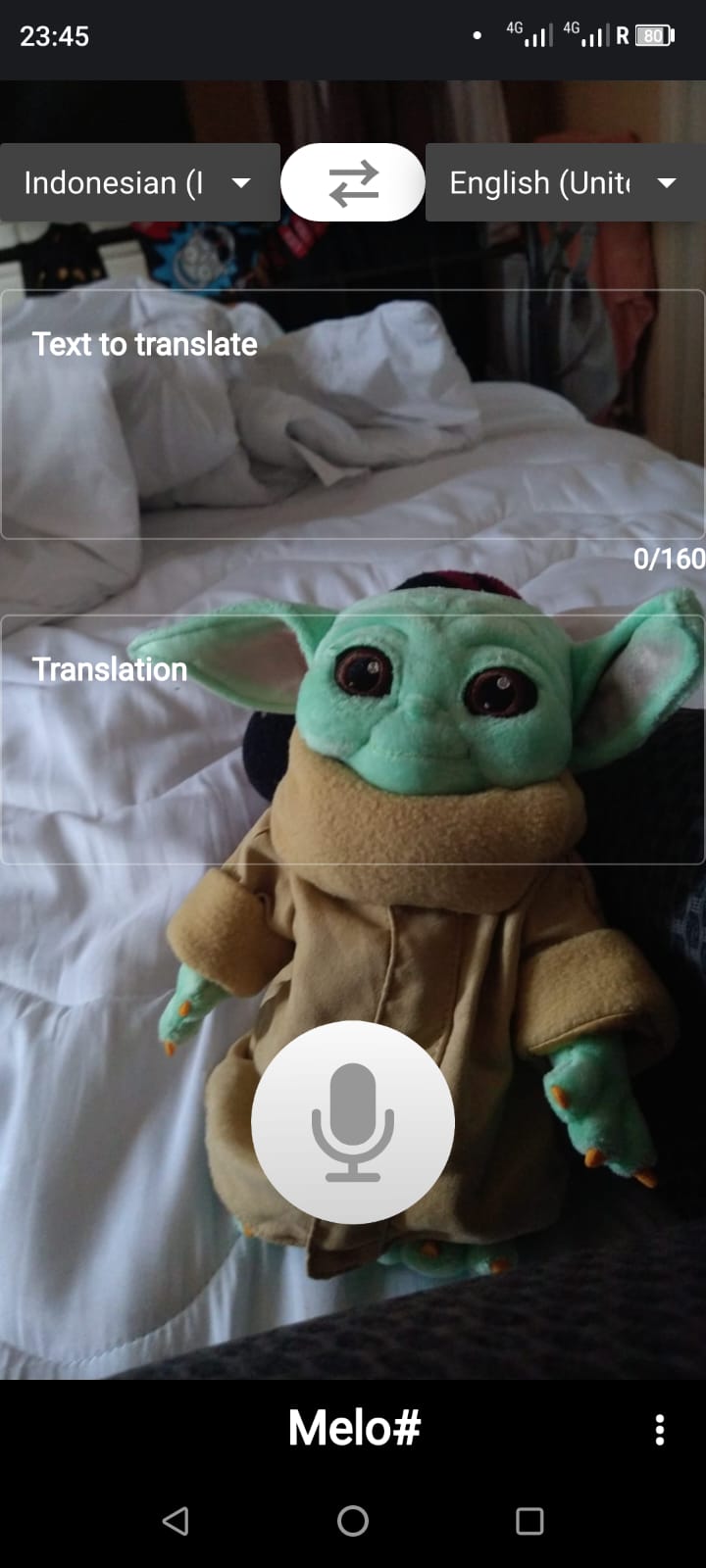 | You can set your own background, instead of the usual plain dark/light one. |
How was this tested?
I would like to thank my familly and friends for their support and feedback, I have learned a lot just watching them using the application in real life scenario. This gave me a lot of ideas to implement new features.